BÀI GIẢNG KINH TẾ LƯỢNG
| Ký hiệu | Ý nghĩa | Ghi chú học nhanh |
|---|---|---|
| Y | Biến phụ thuộc / biến được giải thích | Kết quả ta muốn giải thích hoặc dự báo |
| X | Biến độc lập / biến giải thích | Yếu tố dùng để giải thích Y |
| β₀ | Hệ số chặn tổng thể | Giá trị kỳ vọng của Y khi X = 0, nếu X = 0 có ý nghĩa |
| β₁ | Hệ số góc tổng thể | Mức thay đổi trung bình của Y khi X tăng 1 đơn vị |
| u | Sai số ngẫu nhiên tổng thể | Các yếu tố ảnh hưởng Y nhưng không đưa trực tiếp vào mô hình |
| b₀, b₁ | Ước lượng OLS từ mẫu | Dùng để ước lượng β₀, β₁ |
| Ŷᵢ | Giá trị Y dự báo / giá trị khớp | Ŷᵢ = b₀ + b₁Xᵢ |
| eᵢ | Phần dư mẫu | eᵢ = Yᵢ – Ŷᵢ |
| R² | Hệ số xác định | Tỷ lệ biến thiên của Y được mô hình giải thích trong mẫu |
| Mẹo học ký hiệu
Ký hiệu Hy Lạp β thường nói về tham số tổng thể chưa biết. Ký hiệu b hoặc dấu mũ thường nói về giá trị ước lượng từ mẫu. Sinh viên hay nhầm β₁ với b₁: β₁ là điều ta muốn biết; b₁ là con số ta tính được từ dữ liệu. |
|---|
1. Kinh tế lượng là gì?
1.1. Định nghĩa theo cách dễ hiểu
Kinh tế lượng là ngành học sử dụng lý thuyết kinh tế, toán học, thống kê và dữ liệu thực tế để lượng hóa các quan hệ kinh tế. Nếu kinh tế học đưa ra mệnh đề như “giá tăng làm lượng cầu giảm”, thì kinh tế lượng đặt câu hỏi tiếp theo: giảm bao nhiêu, bằng chứng dữ liệu có đủ mạnh không, kết quả có ổn định không, và có thể dùng để dự báo hay ra quyết định không?
Một định nghĩa thao tác có thể dùng trong lớp học là: kinh tế lượng là quá trình biến một câu hỏi kinh tế thành một mô hình có thể ước lượng, kiểm định và sử dụng bằng dữ liệu.
| Trọng tâm cần nhớ
Kinh tế lượng không chỉ là chạy phần mềm. Phần mềm chỉ tính toán. Người học phải quyết định biến nào đưa vào mô hình, giả thiết nào cần kiểm tra, kết quả nào đáng tin và kết quả nào không nên diễn giải quá mức. |
|---|
1.2. Kinh tế lượng nằm ở đâu trong các môn học?
| Thành phần | Đóng góp vào kinh tế lượng | Ví dụ trong hồi quy đơn |
|---|---|---|
| Lý thuyết kinh tế | Gợi ý mối quan hệ kỳ vọng giữa các biến | Thu nhập tăng có thể làm chi tiêu tăng |
| Toán học | Biểu diễn quan hệ bằng phương trình | Y = β₀ + β₁X + u |
| Thống kê | Suy luận từ mẫu ra tổng thể, đo độ bất định | Kiểm định t, khoảng tin cậy |
| Dữ liệu | Cung cấp bằng chứng thực nghiệm | Dữ liệu về chi tiêu và thu nhập của hộ gia đình |
| Kinh nghiệm nghiên cứu | Nhận diện biến bị bỏ sót, sai đo lường, nội sinh | Không nhầm tương quan với nhân quả |
1.3. Quy trình nghiên cứu kinh tế lượng
- Xác định câu hỏi nghiên cứu: ví dụ “số giờ học có liên hệ thế nào với điểm thi?”
- Dựa vào lý thuyết để xác định biến phụ thuộc Y và biến giải thích X.
- Viết mô hình kinh tế lượng, trong đó có sai số ngẫu nhiên u để đại diện cho các yếu tố không quan sát được.
- Thu thập, làm sạch và mô tả dữ liệu; vẽ đồ thị phân tán trước khi hồi quy.
- Ước lượng mô hình bằng OLS hoặc phương pháp phù hợp.
- Đánh giá kết quả: dấu, độ lớn, ý nghĩa thống kê, R², kiểm tra giả thiết.
- Diễn giải kinh tế, đưa ra kết luận, dự báo hoặc khuyến nghị với mức thận trọng thích hợp.
| Điểm sinh viên thường bỏ qua
Nhiều bài làm bắt đầu ngay bằng lệnh hồi quy và bỏ qua câu hỏi nghiên cứu. Điều này nguy hiểm vì không có lý thuyết định hướng, ta rất dễ chọn biến tùy tiện và diễn giải sai hệ số. |
|---|
1.4. Các dạng dữ liệu thường gặp
| Loại dữ liệu | Mô tả | Ví dụ | Lưu ý khi hồi quy |
|---|---|---|---|
| Dữ liệu chéo | Nhiều đơn vị tại cùng một thời điểm | Thu nhập của 500 hộ năm 2025 | Cần chú ý khác biệt giữa các đơn vị |
| Chuỗi thời gian | Một đơn vị qua nhiều thời điểm | GDP Việt Nam theo quý | Dễ gặp xu thế, mùa vụ, tự tương quan |
| Dữ liệu bảng | Nhiều đơn vị qua nhiều thời điểm | Doanh thu của 100 doanh nghiệp trong 5 năm | Có thể kiểm soát dị biệt cố hữu theo đơn vị/thời gian |
| Dữ liệu thực nghiệm | X được gán ngẫu nhiên | Chương trình hỗ trợ học tập chia nhóm ngẫu nhiên | Mạnh hơn cho suy luận nhân quả nếu thiết kế tốt |
| Dữ liệu quan sát | X phát sinh tự nhiên, không do nhà nghiên cứu kiểm soát | Học thêm và điểm thi | Cần cẩn thận với biến bị bỏ sót và lựa chọn mẫu |
1.5. Tương quan, hồi quy và nhân quả
Tương quan đo mức độ hai biến cùng biến động. Hồi quy mô tả mức thay đổi trung bình của Y gắn với một mức thay đổi của X. Nhân quả là khẳng định rằng thay đổi X làm Y thay đổi, trong điều kiện các yếu tố khác được kiểm soát hợp lý. Ba khái niệm này liên quan nhưng không đồng nhất.
| Cảnh báo quan trọng
Hệ số hồi quy có thể khác 0 và rất có ý nghĩa thống kê, nhưng vẫn không chứng minh được quan hệ nhân quả nếu mô hình bỏ sót biến quan trọng, có quan hệ nhân quả ngược, sai đo lường hoặc lựa chọn mẫu. Trong hồi quy đơn, cụm “khi X tăng 1 đơn vị thì Y thay đổi…” nên được hiểu là quan hệ trung bình trong mẫu, trừ khi thiết kế nghiên cứu cho phép diễn giải nhân quả. |
|---|
2. Bản chất của phân tích hồi quy
2.1. Hồi quy trả lời câu hỏi gì?
Trong hồi quy, ta thường hỏi: “Giá trị trung bình của Y thay đổi như thế nào khi X thay đổi?” Cụm “trung bình” rất quan trọng. Hồi quy không nói rằng mọi cá nhân có cùng X sẽ có cùng Y; nó mô tả xu hướng trung tâm của Y ứng với X.
Ví dụ, nếu Y là điểm thi và X là số giờ học, hồi quy không khẳng định mọi sinh viên học 5 giờ đều đạt cùng một điểm. Nó chỉ ước lượng điểm trung bình kỳ vọng của nhóm sinh viên học 5 giờ, dựa trên dữ liệu quan sát được.
2.2. Hồi quy tổng thể và hồi quy mẫu
| Khái niệm | Ký hiệu | Ý nghĩa |
|---|---|---|
| Hàm hồi quy tổng thể (PRF) | E(Y|Xᵢ) = β₀ + β₁Xᵢ | Quan hệ thật trong tổng thể, thường không quan sát được trực tiếp |
| Mô hình hồi quy tổng thể | Yᵢ = β₀ + β₁Xᵢ + uᵢ | Thêm sai số uᵢ để phản ánh các yếu tố ngoài X |
| Hàm hồi quy mẫu (SRF) | Ŷᵢ = b₀ + b₁Xᵢ | Đường hồi quy tính từ mẫu dữ liệu |
| Phần dư mẫu | eᵢ = Yᵢ – Ŷᵢ | Khoảng cách theo chiều dọc giữa điểm quan sát và đường hồi quy mẫu |
| Phân biệt uᵢ và eᵢ
uᵢ là sai số thật trong tổng thể, thường không quan sát được vì β₀ và β₁ thật cũng không biết. eᵢ là phần dư tính được sau khi ước lượng mô hình bằng mẫu. Trong bài tập, ta tính eᵢ, không tính trực tiếp uᵢ. |
|---|
2.3. Vì sao gọi là “đường hồi quy”?
Với mô hình tuyến tính hai biến, quan hệ kỳ vọng giữa Y và X được biểu diễn bằng một đường thẳng. Hệ số chặn β₀ quyết định vị trí đường thẳng khi X = 0; hệ số góc β₁ quyết định độ dốc. Nếu β₁ > 0, đường dốc lên; nếu β₁ < 0, đường dốc xuống; nếu β₁ = 0, đường nằm ngang theo nghĩa trung bình của Y không thay đổi theo X.
Hình 1. Đường hồi quy OLS đi qua đám mây dữ liệu sao cho tổng bình phương phần dư là nhỏ nhất
2.4. Điều hồi quy làm được và không làm được
| Hồi quy có thể giúp | Hồi quy không tự động giúp |
|---|---|
| Tóm tắt quan hệ trung bình giữa các biến | Chứng minh nhân quả nếu thiết kế dữ liệu yếu |
| Ước lượng mức thay đổi của Y khi X thay đổi | Bảo đảm mô hình đúng về mặt lý thuyết |
| Kiểm định giả thuyết về hệ số hồi quy | Loại bỏ sai lệch do biến bị bỏ sót nếu mô hình thiếu biến |
| Dự báo trong phạm vi dữ liệu phù hợp | Dự báo đáng tin khi ngoại suy quá xa ngoài dữ liệu |
3. Mô hình hồi quy hai biến
3.1. Dạng mô hình
Mô hình trên gọi là “đơn” vì chỉ có một biến giải thích X; gọi là “tuyến tính” vì tuyến tính theo tham số β₀ và β₁. Từ “tuyến tính” trong kinh tế lượng chủ yếu nói về tham số, không nhất thiết yêu cầu biến X chỉ xuất hiện ở dạng nguyên thủy. Ví dụ Y = β₀ + β₁ln(X) + u vẫn tuyến tính theo β.
| Thành phần | Vai trò | Diễn giải |
|---|---|---|
| Yᵢ | Biến phụ thuộc | Kết quả quan sát được ở đơn vị i |
| Xᵢ | Biến giải thích | Yếu tố dùng để giải thích biến thiên của Y |
| β₀ | Hệ số chặn | Giá trị kỳ vọng của Y khi X = 0, nếu X = 0 nằm trong phạm vi hợp lý |
| β₁ | Hệ số góc | Mức thay đổi trung bình của Y khi X tăng 1 đơn vị |
| uᵢ | Sai số ngẫu nhiên | Tác động của các yếu tố khác ngoài X, sai đo lường, yếu tố may rủi |
3.2. Diễn giải hệ số góc β₁
Trong mô hình tuyến tính Yᵢ = β₀ + β₁Xᵢ + uᵢ, hệ số β₁ là thay đổi trong kỳ vọng có điều kiện của Y khi X tăng thêm 1 đơn vị:
| Ví dụ diễn giải
Nếu mô hình ước lượng điểm thi theo số giờ học là Ŷ = 44,25 + 4,75X, thì khi số giờ học tăng thêm 1 giờ/ngày, điểm thi dự báo trung bình tăng 4,75 điểm. Đây là diễn giải theo quan hệ trung bình, không nói rằng từng sinh viên chắc chắn tăng đúng 4,75 điểm. |
|---|
3.3. Diễn giải hệ số chặn β₀
Hệ số chặn là giá trị kỳ vọng của Y khi X = 0. Tuy nhiên, không phải lúc nào X = 0 cũng có ý nghĩa kinh tế. Nếu X là số năm kinh nghiệm, X = 0 có thể hợp lý. Nếu X là diện tích đất trong mẫu chỉ từ 1 ha đến 100 ha, diễn giải tại X = 0 có thể không thực tế. Khi đó, hệ số chặn chủ yếu đóng vai trò kỹ thuật để đường hồi quy đặt đúng vị trí.
| Lỗi hay gặp
Không nên máy móc diễn giải hệ số chặn nếu X = 0 nằm ngoài phạm vi dữ liệu hoặc không có ý nghĩa thực tế. Trong nhiều bài nghiên cứu, trọng tâm nằm ở hệ số góc chứ không phải hệ số chặn. |
|---|
3.4. Sai số ngẫu nhiên u gồm những gì?
- Các biến quan trọng nhưng không được đưa vào mô hình: năng lực cá nhân, động lực học tập, chất lượng giảng dạy.
- Sai số đo lường: số giờ học tự khai báo có thể không chính xác.
- Yếu tố ngẫu nhiên: sức khỏe trong ngày thi, độ khó đề thi, tâm lý.
- Đặc điểm không quan sát được hoặc rất khó lượng hóa.
Vì u chứa nhiều yếu tố khác nhau, giả thiết về quan hệ giữa X và u là trung tâm của hồi quy. Nếu X có tương quan với u, ước lượng OLS của β₁ thường bị chệch, và diễn giải sẽ kém tin cậy.
4. Phương pháp bình phương tối thiểu nhỏ nhất OLS
4.1. Ý tưởng trực giác
OLS chọn đường thẳng Ŷᵢ = b₀ + b₁Xᵢ sao cho các điểm dữ liệu nằm “gần” đường thẳng nhất theo tiêu chuẩn tổng bình phương phần dư. Phần dư là khoảng cách theo chiều dọc giữa giá trị thực tế Yᵢ và giá trị dự báo Ŷᵢ.
| Vì sao bình phương phần dư?
Bình phương làm phần dư âm và dương không triệt tiêu nhau. Bình phương phạt nặng các sai lệch lớn, nên đường hồi quy tránh bỏ mặc những điểm quá xa. Tiêu chuẩn bình phương tạo ra công thức giải tích thuận tiện và các tính chất thống kê mạnh dưới giả thiết phù hợp. |
|---|
4.2. Công thức ước lượng OLS trong hồi quy đơn
Công thức của b₁ cho thấy hệ số góc phụ thuộc vào mức độ X và Y cùng biến động quanh trung bình. Tử số là đồng biến thiên giữa X và Y; mẫu số là biến thiên của X. Nếu X gần như không thay đổi trong mẫu, mẫu số rất nhỏ và rất khó ước lượng tác động của X lên Y.
4.3. Tính chất đại số của đường OLS
- Tổng phần dư bằng 0: Σeᵢ = 0. Do đó trung bình phần dư bằng 0 nếu mô hình có hệ số chặn.
- Tổng tích giữa X và phần dư bằng 0: ΣXᵢeᵢ = 0. Nói cách khác, phần dư không còn tương quan tuyến tính với X trong mẫu.
- Đường hồi quy OLS đi qua điểm trung bình mẫu: (X̄, Ȳ).
- Tổng biến thiên của Y quanh trung bình có thể phân rã thành phần được giải thích và phần không được giải thích.
| Không nên hiểu sai
Việc phần dư không tương quan với X trong mẫu là hệ quả toán học của OLS, không có nghĩa là sai số tổng thể u chắc chắn không tương quan với X. Giả thiết cần cho suy luận là E(u|X)=0 trong tổng thể, mạnh hơn nhiều so với tính chất phần dư trong mẫu. |
|---|
4.4. Quy trình tính OLS bằng tay
- Tính trung bình X̄ và Ȳ.
- Tính độ lệch từng quan sát so với trung bình: Xᵢ – X̄ và Yᵢ – Ȳ.
- Tính Sxx = Σ(Xᵢ – X̄)² và Sxy = Σ(Xᵢ – X̄)(Yᵢ – Ȳ).
- Tính b₁ = Sxy/Sxx.
- Tính b₀ = Ȳ – b₁X̄.
- Viết phương trình ước lượng: Ŷ = b₀ + b₁X.
- Tính Ŷᵢ, eᵢ, RSS nếu cần đánh giá sai số và R².
5. Các giả thiết cổ điển của định lý Gauss-Markov
5.1. Định lý Gauss-Markov nói gì?
Trong mô hình hồi quy tuyến tính, nếu các giả thiết Gauss-Markov phù hợp, ước lượng OLS là BLUE: Best Linear Unbiased Estimator. Nghĩa là trong lớp các ước lượng tuyến tính và không chệch, OLS có phương sai nhỏ nhất.
| Chữ | Nghĩa | Diễn giải trong lớp học |
|---|---|---|
| B – Best | Tốt nhất | Có phương sai nhỏ nhất trong lớp đang xét |
| L – Linear | Tuyến tính | Ước lượng là hàm tuyến tính của các giá trị Yᵢ |
| U – Unbiased | Không chệch | Trung bình qua nhiều mẫu bằng đúng tham số thật |
| E – Estimator | Ước lượng | Quy tắc dùng mẫu để ước lượng tham số tổng thể |
| Cần nhớ
Gauss-Markov không nói OLS luôn đúng trong mọi tình huống. Nó nói OLS có tính chất tốt nếu các giả thiết nhất định thỏa mãn. Khi giả thiết bị vi phạm, ta phải xem loại vi phạm nào xảy ra và hậu quả là chệch, kém hiệu quả, hay sai kiểm định. |
|---|
5.2. Các giả thiết cốt lõi trong hồi quy đơn
| Giả thiết | Phát biểu ngắn | Ý nghĩa trực giác | Nếu vi phạm |
|---|---|---|---|
|
Y = β₀ + β₁X + u | Mô hình có dạng ước lượng được bằng OLS | Sai dạng hàm có thể làm hệ số sai lệch |
|
(Xᵢ,Yᵢ) là mẫu đại diện | Dữ liệu phản ánh tổng thể cần nghiên cứu | Kết quả có thể không khái quát được |
|
Không phải mọi Xᵢ đều bằng nhau | Cần dữ liệu có khác biệt về X để học được độ dốc | Không tính được b₁ vì Sxx = 0 |
|
E(u|X)=0 | X không chứa thông tin hệ thống về phần bị bỏ sót | OLS thường bị chệch và không nhất quán |
|
Var(u|X)=σ² | Độ nhiễu của Y quanh đường hồi quy ổn định theo X | OLS vẫn có thể không chệch nhưng sai số chuẩn thông thường sai và kém hiệu quả |
|
Cov(uᵢ,uⱼ|X)=0 với i ≠ j | Sai số của quan sát này không kéo theo sai số quan sát khác | Đặc biệt quan trọng với chuỗi thời gian; sai số chuẩn có thể sai |
|
u|X ~ Normal(0,σ²) | Hữu ích cho kiểm định chính xác trong mẫu nhỏ | Với mẫu lớn có thể dựa vào xấp xỉ, nhưng mẫu nhỏ cần thận trọng |
5.3. Giả thiết E(u|X)=0 là linh hồn của hồi quy
Giả thiết E(u|X)=0 nói rằng, tại mỗi mức X, các yếu tố bị đưa vào sai số u có trung bình bằng 0 và không liên hệ hệ thống với X. Đây là điều kiện quan trọng để OLS không chệch. Trong ngôn ngữ trực giác, X phải “sạch” đối với phần còn lại của mô hình.
| Ví dụ biến bị bỏ sót
Hồi quy điểm thi Y theo số giờ học X. Nếu năng lực bẩm sinh và động lực học tập không được đưa vào mô hình, đồng thời các yếu tố này lại liên hệ với số giờ học, thì u có tương quan với X. Khi đó b₁ có thể phản ánh cả tác động của giờ học lẫn tác động của năng lực/động lực, nên không thể diễn giải nhân quả đơn giản. |
|---|
5.4. Phương sai đồng nhất và phương sai thay đổi
Phương sai đồng nhất nghĩa là mức độ phân tán của Y quanh đường hồi quy không thay đổi có hệ thống theo X. Nếu ở nhóm X nhỏ, điểm dữ liệu rất sát đường hồi quy, còn ở nhóm X lớn, điểm dữ liệu phân tán rất mạnh, ta nghi ngờ có phương sai thay đổi.
| Tình huống | Hậu quả thường gặp | Cách xử lý cơ bản ở các học phần sau |
|---|---|---|
| Phương sai đồng nhất | Sai số chuẩn OLS thông thường phù hợp | Dùng kiểm định t, F thông thường |
| Phương sai thay đổi | OLS có thể vẫn không chệch nếu E(u|X)=0, nhưng sai số chuẩn thông thường sai | Dùng sai số chuẩn vững, biến đổi mô hình, hoặc WLS nếu có cấu trúc phù hợp |
5.5. Normality: giả thiết chuẩn có phải luôn bắt buộc?
Giả thiết sai số phân phối chuẩn thường được đưa vào mô hình cổ điển để suy luận t và F chính xác trong mẫu nhỏ. Tuy nhiên, để OLS không chệch, ta không cần sai số chuẩn; điều kiện quan trọng hơn là E(u|X)=0. Với mẫu đủ lớn, nhờ định lý giới hạn trung tâm, nhiều kiểm định có thể dùng xấp xỉ ngay cả khi sai số không hoàn toàn chuẩn.
| Cách nhớ
Không chuẩn không nhất thiết làm hệ số OLS bị chệch. Nhưng trong mẫu nhỏ, không chuẩn có thể làm p-value và khoảng tin cậy dựa trên t kém chính xác. Đừng xếp mọi giả thiết vào cùng một loại hậu quả. |
|---|
6. Ước lượng và tính chất của các ước lượng OLS
6.1. Ước lượng điểm và sai số chuẩn
Kết quả OLS luôn gồm ít nhất hai loại thông tin: ước lượng điểm và độ bất định của ước lượng. Ước lượng điểm b₁ cho biết hệ số góc tính được từ mẫu. Sai số chuẩn se(b₁) cho biết b₁ dao động mạnh đến mức nào nếu ta lặp lại việc lấy mẫu nhiều lần.
Công thức cho thấy muốn ước lượng hệ số góc chính xác hơn, ta cần hai điều: sai số của mô hình nhỏ hơn, và biến X có nhiều biến thiên hơn. Nếu mọi quan sát có X gần giống nhau, dữ liệu không cung cấp đủ thông tin để xác định độ dốc.
6.2. Ước lượng không chệch
Một ước lượng được gọi là không chệch nếu trung bình của nó qua rất nhiều mẫu giả định bằng đúng tham số thật. Với b₁, không chệch nghĩa là E(b₁) = β₁. Điều này không có nghĩa là b₁ của một mẫu cụ thể chắc chắn bằng β₁. Nó chỉ nói rằng quy trình ước lượng không lệch có hệ thống về một phía.
| Ví dụ trực giác
Bắn cung vào bia: không chệch nghĩa là nếu bắn rất nhiều mũi tên, tâm của các mũi tên trùng với hồng tâm. Một mũi tên riêng lẻ vẫn có thể lệch. Sai số chuẩn đo mức độ các mũi tên phân tán quanh tâm. |
|---|
6.3. Hiệu quả và BLUE
Trong lớp các ước lượng tuyến tính không chệch, OLS có phương sai nhỏ nhất nếu giả thiết Gauss-Markov thỏa mãn. “Hiệu quả” ở đây nghĩa là ước lượng dao động ít hơn quanh tham số thật. Một ước lượng khác cũng không chệch nhưng có phương sai lớn hơn sẽ kém chính xác hơn OLS trong cùng điều kiện.
Tuy nhiên, nếu có phương sai thay đổi hoặc tự tương quan, OLS có thể vẫn không chệch nhưng không còn hiệu quả nhất; đồng thời sai số chuẩn thông thường có thể không đúng. Đây là lý do các học phần sau học thêm sai số chuẩn vững, GLS hoặc các mô hình chuyên biệt.
6.4. Ước lượng phương sai sai số
Mẫu số n – 2 là bậc tự do còn lại sau khi đã ước lượng hai tham số. Đây là điểm sinh viên hay quên khi tính bằng tay. Nếu dùng n thay vì n – 2, ta thường đánh giá thấp phương sai sai số.
7. Hệ số xác định mô hình R²
7.1. Phân rã biến thiên
R² dựa trên ý tưởng phân rã biến thiên của Y quanh trung bình. Tổng biến thiên của Y được chia thành phần mô hình giải thích được và phần còn lại nằm trong phần dư.
7.2. Công thức và diễn giải R²
R² cho biết tỷ lệ biến thiên của Y trong mẫu được giải thích bởi mô hình. Nếu R² = 0,70, ta nói mô hình giải thích khoảng 70% biến thiên của Y quanh trung bình trong mẫu. R² càng cao, đường hồi quy càng khớp với dữ liệu mẫu theo nghĩa bình phương phần dư càng nhỏ tương đối so với tổng biến thiên của Y.
| Ba điều R² không nói
R² cao không chứng minh mô hình đúng về nhân quả. R² cao không bảo đảm dự báo ngoài mẫu tốt. R² thấp không nhất thiết làm hệ số quan tâm vô nghĩa; trong dữ liệu vi mô, nhiều hiện tượng có nhiễu lớn nên R² thấp vẫn có thể bình thường. |
|---|
7.3. R² trong hồi quy đơn và hệ số tương quan
Trong hồi quy đơn có hệ số chặn, R² bằng bình phương hệ số tương quan mẫu giữa X và Y. Vì vậy R² không cho biết dấu của quan hệ; dấu nằm ở hệ số b₁. Nếu tương quan là -0,8 thì R² = 0,64, nhưng quan hệ là nghịch biến.
| Lỗi hay gặp
Không được nói “R² = 0,64 nghĩa là X làm Y tăng 64%”. Cách nói đúng là “mô hình hồi quy tuyến tính với X giải thích 64% biến thiên của Y trong mẫu”. |
|---|
8. Kiểm định giả thuyết ý nghĩa thống kê của hệ số hồi quy bằng kiểm định t
8.1. Vì sao cần kiểm định?
Một mẫu dữ liệu gần như luôn tạo ra một hệ số b₁ nào đó, kể cả khi trong tổng thể không có quan hệ. Kiểm định t giúp ta đánh giá liệu hệ số ước lượng có đủ lớn so với độ bất định của nó để bác bỏ giả thuyết hệ số tổng thể bằng một giá trị nào đó, thường là 0.
Giả thuyết H₀: β₁ = 0 nghĩa là X không có quan hệ tuyến tính với kỳ vọng của Y trong mô hình. Nếu bác bỏ H₀, ta nói hệ số có ý nghĩa thống kê ở mức ý nghĩa đã chọn.
8.2. Thống kê kiểm định t
Nếu |t| lớn, hệ số ước lượng nằm xa giá trị giả thuyết so với sai số chuẩn, nên dữ liệu ít phù hợp với H₀. Nếu |t| nhỏ, hệ số ước lượng có thể chỉ là dao động ngẫu nhiên quanh giá trị giả thuyết.
| Cách tiếp cận | Quy tắc quyết định | Diễn giải |
|---|---|---|
| So sánh giá trị tới hạn | |t| > t_{α/2, n-2} thì bác bỏ H₀ | Dùng bảng t hoặc phần mềm |
| Dùng p-value | p-value < α thì bác bỏ H₀ | p-value càng nhỏ, bằng chứng chống lại H₀ càng mạnh |
| Dùng khoảng tin cậy | Nếu 0 không nằm trong KTC 95% thì bác bỏ H₀ ở mức 5% | Liên hệ trực tiếp giữa kiểm định hai phía và khoảng tin cậy |
8.3. Mức ý nghĩa, p-value và lỗi suy luận
Mức ý nghĩa α là xác suất tối đa chấp nhận mắc sai lầm loại I: bác bỏ H₀ khi H₀ đúng. Các mức thông dụng là 10%, 5% và 1%. p-value là xác suất, giả sử H₀ đúng, quan sát được thống kê kiểm định cực đoan ít nhất như dữ liệu đang có. p-value không phải xác suất H₀ đúng.
| Diễn giải p-value đúng
Nếu p-value = 0,03, không nên nói “xác suất H₀ đúng là 3%”. Cách nói phù hợp: nếu H₀ đúng, xác suất quan sát được bằng chứng cực đoan như mẫu hiện tại hoặc hơn là 3%; vì 3% < 5%, ta bác bỏ H₀ ở mức ý nghĩa 5%. |
|---|
8.4. Ý nghĩa thống kê khác ý nghĩa kinh tế
Một hệ số có thể có ý nghĩa thống kê nhưng quá nhỏ để có ý nghĩa thực tiễn. Ngược lại, một hệ số có độ lớn đáng kể về kinh tế nhưng không có ý nghĩa thống kê do mẫu nhỏ hoặc dữ liệu nhiều nhiễu. Vì vậy, khi báo cáo kết quả, cần xem cả dấu, độ lớn, đơn vị đo, sai số chuẩn, p-value và bối cảnh kinh tế.
| Trường hợp | Ý nghĩa thống kê | Ý nghĩa kinh tế | Cách đọc |
|---|---|---|---|
| b₁ lớn, p nhỏ | Có | Có thể có | Kết quả mạnh, vẫn cần kiểm tra giả thiết |
| b₁ nhỏ, p nhỏ | Có | Có thể không | Mẫu lớn có thể làm hiệu ứng nhỏ trở nên có ý nghĩa |
| b₁ lớn, p lớn | Không | Có thể có | Dữ liệu chưa đủ chính xác; cần mẫu lớn hơn hoặc mô hình tốt hơn |
| b₁ nhỏ, p lớn | Không | Thường không | Ít bằng chứng về quan hệ trong dữ liệu |
9. Khoảng tin cậy của các hệ số
9.1. Ý tưởng
Khoảng tin cậy cung cấp một khoảng giá trị hợp lý cho tham số tổng thể, thay vì chỉ một ước lượng điểm. Với mức tin cậy 95%, nếu lặp lại quá trình lấy mẫu và lập khoảng rất nhiều lần theo cùng phương pháp, khoảng tin cậy sẽ chứa tham số thật khoảng 95% số lần.
Độ rộng khoảng tin cậy phụ thuộc vào sai số chuẩn và mức tin cậy. Mức tin cậy càng cao, khoảng càng rộng. Sai số chuẩn càng lớn, khoảng càng rộng. Do đó dữ liệu nhiễu hoặc mẫu nhỏ làm kết luận kém chính xác.
9.2. Diễn giải đúng và sai
| Cách nói | Đúng hay sai? | Lý do |
|---|---|---|
| “Khoảng 95% này chứa β₁ thật với xác suất 95%.” | Không chuẩn trong thống kê tần suất | β₁ là hằng số; khoảng mới ngẫu nhiên trước khi lấy mẫu |
| “Phương pháp lập khoảng 95% sẽ chứa β₁ thật trong khoảng 95% số mẫu lặp lại.” | Đúng | Nhấn mạnh tính chất của quy trình lấy mẫu |
| “Các giá trị trong khoảng là những giá trị hợp lý của β₁ theo dữ liệu và mô hình.” | Dùng được trong giảng dạy | Diễn giải thực hành dễ hiểu |
| “Nếu 0 nằm ngoài KTC 95%, hệ số có ý nghĩa ở mức 5% trong kiểm định hai phía.” | Đúng | Tương đương với kiểm định t hai phía |
9.3. Khoảng tin cậy cho hệ số chặn
Khoảng tin cậy cho hệ số chặn thường ít được quan tâm hơn hệ số góc, trừ khi giá trị X = 0 có ý nghĩa kinh tế. Trong nhiều bài ứng dụng, hệ số chặn cần có trong mô hình nhưng không nhất thiết cần diễn giải sâu.
10. Dự báo dựa trên mô hình hồi quy đơn
10.1. Dự báo điểm
Sau khi có phương trình hồi quy mẫu Ŷ = b₀ + b₁X, ta có thể dự báo giá trị trung bình của Y tại một mức X₀ bằng cách thay X₀ vào phương trình.
Dự báo điểm là một con số trung tâm, không phản ánh toàn bộ bất định. Trong ứng dụng, cần phân biệt dự báo trung bình của nhóm có X₀ và dự báo cho một cá thể cụ thể có X₀.
10.2. Dự báo trung bình và dự báo cá biệt
| Loại dự báo | Câu hỏi trả lời | Khoảng thường hẹp/rộng? | Lý do |
|---|---|---|---|
| Khoảng tin cậy cho trung bình E(Y|X₀) | Trung bình của tất cả đơn vị có X = X₀ là bao nhiêu? | Hẹp hơn | Chỉ tính bất định của đường hồi quy ước lượng |
| Khoảng dự báo cho một quan sát cá biệt Y₀ | Một cá nhân/đơn vị cụ thể có X = X₀ sẽ có Y là bao nhiêu? | Rộng hơn | Bao gồm cả bất định của đường hồi quy và sai số cá biệt u₀ |
| Điểm dễ nhầm
Khoảng dự báo cá biệt luôn rộng hơn khoảng tin cậy cho trung bình tại cùng X₀, vì dự báo một cá thể phải cộng thêm nhiễu riêng của cá thể đó. |
|---|
10.3. Ngoại suy và giới hạn của dự báo
Dự báo đáng tin nhất khi X₀ nằm trong phạm vi dữ liệu đã dùng để ước lượng. Nếu mô hình được ước lượng từ số giờ học trong khoảng 2 đến 9 giờ/ngày, dự báo cho 10 giờ có thể còn gần phạm vi mẫu, nhưng dự báo cho 20 giờ là ngoại suy mạnh và có thể vô nghĩa. Ngoại suy bỏ qua khả năng quan hệ không còn tuyến tính ở vùng dữ liệu chưa quan sát.
| Nguyên tắc thực hành
Trước khi dự báo, hãy kiểm tra: X₀ có nằm trong phạm vi dữ liệu không, mô hình có ý nghĩa kinh tế không, quan hệ có thể phi tuyến không, và sai số dự báo có đủ nhỏ cho mục đích sử dụng không. |
|---|
11. Ví dụ tính toán đầy đủ
11.1. Dữ liệu ví dụ
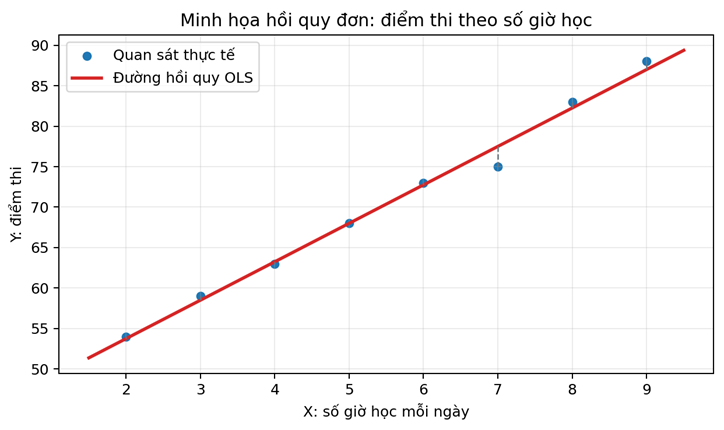
Giả sử ta khảo sát 8 sinh viên. X là số giờ học trung bình mỗi ngày trước kỳ thi; Y là điểm thi. Dữ liệu như sau:
| Sinh viên | X: giờ học/ngày | Y: điểm thi |
|---|---|---|
| 1 | 2 | 54 |
| 2 | 3 | 59 |
| 3 | 4 | 63 |
| 4 | 5 | 68 |
| 5 | 6 | 73 |
| 6 | 7 | 75 |
| 7 | 8 | 83 |
| 8 | 9 | 88 |
11.2. Ước lượng mô hình
Với dữ liệu trên, tính được X̄ = 5,5 và Ȳ = 70,375. Kết quả OLS là:
| Chỉ tiêu | Giá trị | Diễn giải |
|---|---|---|
| b₀ | 44,25 | Điểm dự báo khi X = 0; chủ yếu là thành phần kỹ thuật trong ví dụ này |
| b₁ | 4,75 | Khi giờ học tăng 1 giờ/ngày, điểm dự báo trung bình tăng 4,75 điểm |
| RSS | 8,25 | Tổng bình phương phần dư |
| TSS | 955,875 | Tổng biến thiên của điểm thi quanh trung bình |
| R² | 0,9914 | Mô hình giải thích khoảng 99,14% biến thiên của điểm thi trong mẫu |
| s² | 1,375 | Ước lượng phương sai sai số với bậc tự do n – 2 = 6 |
| s | 1,1726 | Sai số chuẩn của hồi quy |
| Lưu ý về R² trong ví dụ
R² rất cao vì dữ liệu ví dụ được thiết kế đơn giản để minh họa tính toán. Dữ liệu thực tế trong kinh tế thường nhiễu hơn nhiều, nên R² thấp hơn là chuyện bình thường. |
|---|
11.3. Bảng giá trị dự báo và phần dư
| i | Xᵢ | Yᵢ | Ŷᵢ = 44,25 + 4,75Xᵢ | eᵢ = Yᵢ – Ŷᵢ |
|---|---|---|---|---|
| 1 | 2 | 54 | 53,75 | 0,25 |
| 2 | 3 | 59 | 58,50 | 0,50 |
| 3 | 4 | 63 | 63,25 | -0,25 |
| 4 | 5 | 68 | 68,00 | 0,00 |
| 5 | 6 | 73 | 72,75 | 0,25 |
| 6 | 7 | 75 | 77,50 | -2,50 |
| 7 | 8 | 83 | 82,25 | 0,75 |
| 8 | 9 | 88 | 87,00 | 1,00 |
Tổng phần dư bằng 0, đúng với tính chất OLS khi mô hình có hệ số chặn. Quan sát thứ 6 có phần dư âm lớn nhất trong ví dụ: điểm thực tế thấp hơn dự báo 2,5 điểm.
11.4. Kiểm định t cho hệ số góc
Ta kiểm định H₀: β₁ = 0 so với H₁: β₁ ≠ 0. Từ dữ liệu, se(b₁) = 0,1809, nên:
Giá trị t rất lớn về trị tuyệt đối, p-value xấp xỉ 0,0000002. Do đó ta bác bỏ H₀ ở các mức ý nghĩa thông dụng. Có bằng chứng thống kê rất mạnh rằng số giờ học có quan hệ tuyến tính dương với điểm thi trong dữ liệu ví dụ này.
11.5. Khoảng tin cậy 95% cho β₁
Với df = 6, giá trị tới hạn t_{0,025;6} ≈ 2,447. Khoảng tin cậy 95% cho β₁ là:
Khoảng này không chứa 0, phù hợp với kết quả kiểm định t hai phía ở mức 5%. Diễn giải thực hành: trong phạm vi dữ liệu, mỗi giờ học thêm gắn với điểm trung bình tăng khoảng từ 4,31 đến 5,19 điểm.
11.6. Dự báo tại X₀ = 10 giờ/ngày
| Loại khoảng | Giá trị xấp xỉ | Diễn giải |
|---|---|---|
| KTC 95% cho trung bình E(Y|X=10) | [89,51 ; 93,99] | Khoảng cho điểm trung bình của nhóm sinh viên học 10 giờ/ngày |
| Khoảng dự báo 95% cho cá thể | [88,11 ; 95,39] | Khoảng cho điểm của một sinh viên cụ thể học 10 giờ/ngày |
| Nhận xét
Khoảng dự báo cá thể rộng hơn vì một sinh viên cụ thể còn chịu ảnh hưởng bởi nhiều yếu tố ngoài giờ học: năng lực, sức khỏe, tâm lý, đề thi, chất lượng ôn tập. |
|---|
12. Những điểm sinh viên thường khó hiểu
| Vấn đề hay nhầm | Cách hiểu sai | Cách hiểu đúng |
|---|---|---|
| Sai số u và phần dư e | Tưởng u và e là một | u là sai số tổng thể không quan sát được; e là phần dư mẫu tính được sau OLS |
| Hệ số chặn | Luôn diễn giải máy móc tại X=0 | Chỉ diễn giải sâu nếu X=0 có ý nghĩa và nằm trong phạm vi phù hợp |
| Hệ số góc | Nói mọi cá nhân thay đổi đúng b₁ | b₁ là thay đổi trung bình dự báo của Y khi X tăng 1 đơn vị |
| R² | R² cao nghĩa là nhân quả mạnh | R² chỉ đo độ khớp trong mẫu, không chứng minh nhân quả |
| p-value | p-value là xác suất H₀ đúng | p-value là xác suất thấy bằng chứng cực đoan nếu H₀ đúng |
| Không bác bỏ H₀ | Chứng minh H₀ đúng | Chỉ nói dữ liệu chưa đủ bằng chứng để bác bỏ H₀ |
| Ý nghĩa thống kê | Đồng nghĩa với quan trọng thực tế | Cần xét độ lớn hệ số, đơn vị đo và bối cảnh kinh tế |
| Dự báo | Dự báo điểm là chắc chắn | Dự báo luôn có bất định; cần khoảng tin cậy hoặc khoảng dự báo |
| OLS tốt nhất | OLS luôn tốt nhất | OLS là BLUE khi giả thiết Gauss-Markov thỏa mãn trong lớp ước lượng xét đến |
13. Tóm tắt công thức cần nhớ
| Nội dung | Công thức | Ghi chú |
|---|---|---|
| Mô hình tổng thể | Yᵢ = β₀ + β₁Xᵢ + uᵢ | u chứa các yếu tố ngoài X |
| Đường hồi quy mẫu | Ŷᵢ = b₀ + b₁Xᵢ | Đường ước lượng từ dữ liệu |
| Phần dư | eᵢ = Yᵢ – Ŷᵢ | Sai lệch quan sát so với dự báo |
| Hệ số góc OLS | b₁ = Σ(Xᵢ-X̄)(Yᵢ-Ȳ) / Σ(Xᵢ-X̄)² | Đồng biến thiên chia cho biến thiên X |
| Hệ số chặn OLS | b₀ = Ȳ – b₁X̄ | Đường OLS đi qua (X̄,Ȳ) |
| RSS | RSS = Σeᵢ² | Tổng bình phương phần dư |
| Phương sai sai số | s² = RSS/(n-2) | Hồi quy đơn ước lượng 2 tham số |
| R² | R² = 1 – RSS/TSS | Độ khớp trong mẫu |
| Thống kê t | t = (bⱼ – βⱼ,0)/se(bⱼ) | df = n – 2 trong hồi quy đơn |
| Khoảng tin cậy | bⱼ ± t_{α/2,n-2}se(bⱼ) | Cho hệ số βⱼ |
| Dự báo điểm | Ŷ₀ = b₀ + b₁X₀ | Cần tránh ngoại suy quá xa |
14. Bài tập cuối phần
14.1. Câu hỏi lý thuyết ngắn
- Kinh tế lượng khác gì với thống kê mô tả? Hãy nêu một ví dụ minh họa.
- Vì sao hồi quy không tự động chứng minh nhân quả? Nêu ít nhất hai nguyên nhân.
- Phân biệt hàm hồi quy tổng thể PRF và hàm hồi quy mẫu SRF.
- Phân biệt sai số ngẫu nhiên uᵢ và phần dư eᵢ.
- Vì sao OLS tối thiểu hóa tổng bình phương phần dư chứ không tối thiểu hóa tổng phần dư?
- Phát biểu và diễn giải giả thiết E(u|X)=0 trong hồi quy đơn.
- R² = 0,80 có nghĩa là gì? Có nghĩa là X gây ra 80% thay đổi của Y không? Giải thích.
- p-value = 0,04 trong kiểm định H₀: β₁ = 0 có nên diễn giải là xác suất H₀ đúng bằng 4% không? Vì sao?
- Tại sao khoảng dự báo cho một cá thể thường rộng hơn khoảng tin cậy cho trung bình?
- Trong trường hợp nào không nên diễn giải hệ số chặn?
14.2. Bài tập tính toán
Bài 1. Một giảng viên thu thập dữ liệu về số giờ tự học X và điểm kiểm tra Y của 6 sinh viên như sau:
| Sinh viên | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| X | 1 | 2 | 3 | 4 | 5 | 6 |
| Y | 48 | 52 | 57 | 61 | 65 | 70 |
- Tính X̄, Ȳ, Sxx và Sxy.
- Ước lượng mô hình Ŷ = b₀ + b₁X.
- Diễn giải b₁ trong bối cảnh bài toán.
- Tính giá trị dự báo khi X = 7.
- Tính các phần dư và kiểm tra tổng phần dư có xấp xỉ bằng 0 không.
- Tính RSS, TSS và R².
Bài 2. Một mô hình hồi quy tiền lương theo số năm kinh nghiệm cho kết quả:
- Kiểm định H₀: β₁ = 0 so với H₁: β₁ ≠ 0 ở mức ý nghĩa 5%.
- Tính khoảng tin cậy 95% cho β₁, biết t_{0,025;28} ≈ 2,048.
- Diễn giải kết quả theo ý nghĩa thống kê và ý nghĩa kinh tế.
- Có thể kết luận “kinh nghiệm làm tăng lương” theo nghĩa nhân quả không? Cần điều kiện gì?
Bài 3. Một mô hình dự báo chi tiêu tiêu dùng theo thu nhập có R² = 0,35. Một sinh viên kết luận: “Mô hình này vô dụng vì R² thấp.” Hãy phản biện kết luận này trong khoảng 8 đến 10 dòng.
14.3. Gợi ý đáp án nhanh
| Bài 1 – kiểm tra kết quả
Với dữ liệu Bài 1: X̄ = 3,5; Ȳ ≈ 58,83; b₁ ≈ 4,314; b₀ ≈ 43,733; phương trình Ŷ ≈ 43,733 + 4,314X. Khi X = 7, dự báo Ŷ ≈ 73,93. Sinh viên nên tự tính RSS, TSS, R² để luyện quy trình. |
|---|
| Bài 2 – gợi ý
t = 0,8/0,25 = 3,2. Vì 3,2 > 2,048, bác bỏ H₀ ở mức 5%. KTC 95%: 0,8 ± 2,048×0,25 = [0,288 ; 1,312]. Diễn giải: thêm 1 năm kinh nghiệm gắn với lương trung bình cao hơn khoảng 0,8 triệu đồng/tháng; khoảng giá trị hợp lý từ 0,288 đến 1,312 triệu, trong điều kiện mô hình phù hợp. |
|---|
15. Checklist tự học trước khi sang hồi quy bội
- Tôi có thể tự viết và giải thích mô hình Yᵢ = β₀ + β₁Xᵢ + uᵢ.
- Tôi phân biệt được β₁ và b₁, uᵢ và eᵢ, PRF và SRF.
- Tôi tính được b₀, b₁ bằng công thức OLS trong hồi quy đơn.
- Tôi hiểu trực giác của giả thiết E(u|X)=0 và vì sao nó quan trọng hơn việc chỉ nhìn R².
- Tôi đọc được bảng kết quả hồi quy: coefficient, standard error, t-statistic, p-value, R².
- Tôi biết cách diễn giải hệ số, kiểm định t, khoảng tin cậy và dự báo trong ngôn ngữ kinh tế.
- Tôi biết những câu không nên nói: “R² chứng minh nhân quả”, “p-value là xác suất H₀ đúng”, “không bác bỏ H₀ nghĩa là H₀ đúng”.
16. Gợi ý tài liệu học sâu
- Gujarati & Porter – Basic Econometrics: phù hợp để đọc nền tảng và luyện bài tập kinh tế lượng cổ điển.
- Wooldridge – Introductory Econometrics: A Modern Approach: mạnh về trực giác kinh tế, giả thiết và vấn đề nhân quả.
- Stock & Watson – Introduction to Econometrics: tốt cho cách tiếp cận hiện đại, ví dụ thực nghiệm và suy luận thống kê.
- Khi học bằng phần mềm, hãy luôn tự hỏi: biến phụ thuộc là gì, hệ số đang đo điều gì, giả thiết nào đang được dùng, và kết luận có vượt quá dữ liệu hay không.